
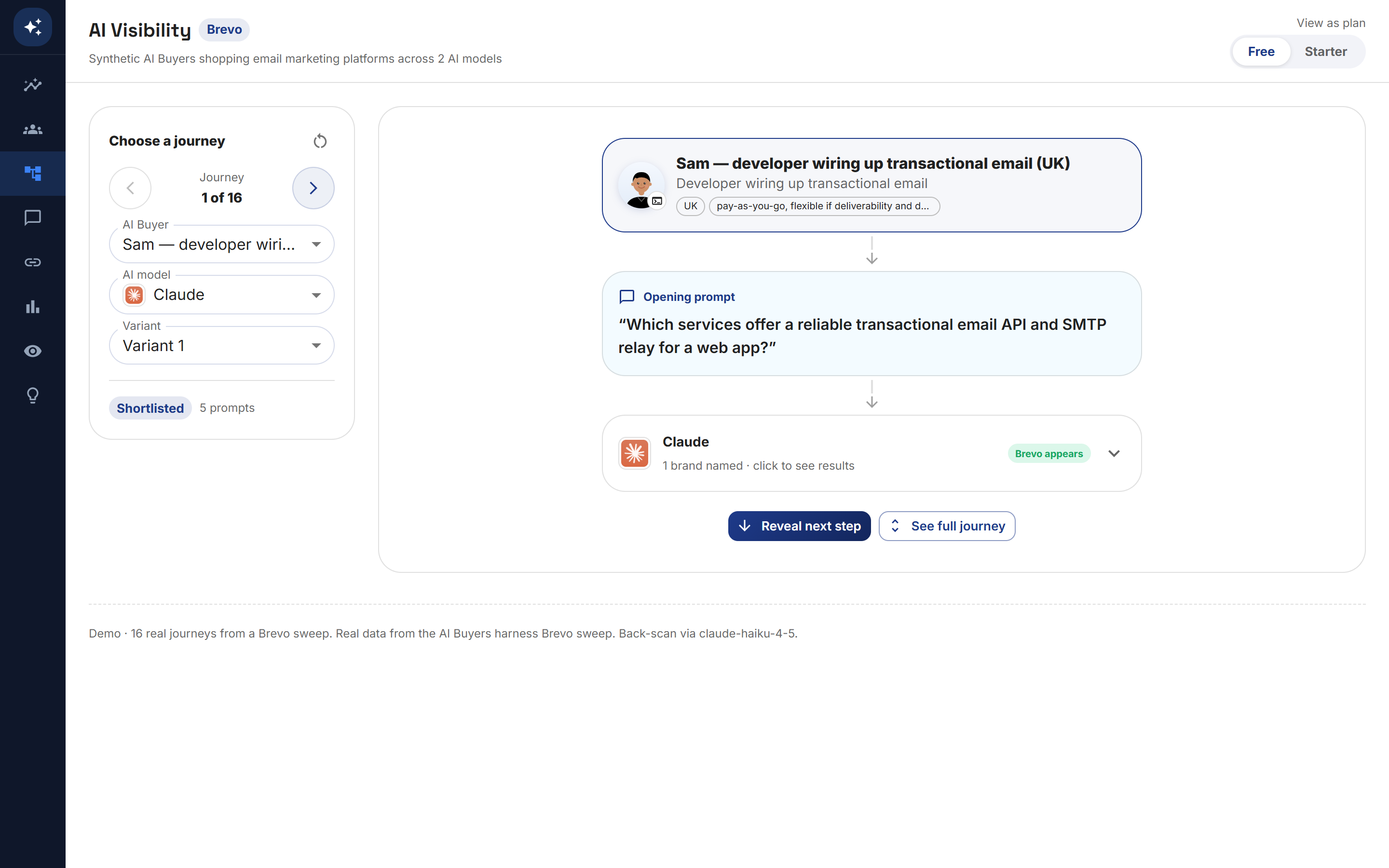
A buyer typed this into Claude: "I'm looking for networking opportunities and freelance work. My budget is 0. What would you recommend, and why (I'm in UK)?"
Claude answered with a tidy plan and eight named brands. The buyer asked four follow-up questions, each more specific than the last. By the end of the conversation the AI had named a shortlist, weighed the trade-offs and recommended one platform, with reasons.
The buyer was synthetic, one of our AI Buyers. The conversation, the models and the answers were entirely real. As a worked example, we ran 59 of these buying journeys in one UK hiring category, with a real platform in that space as the brand being measured (name hidden), across five AI models: ChatGPT, Claude, Perplexity, Gemini and Grok. The models named 316 different brands, made 45 clear decisions, and explained every one of them.
This article is about what those journeys reveal: AI buyers are a genuinely different kind of buyer, and measuring them, the discipline usually called AI search visibility, GEO (generative engine optimisation) or AEO (answer engine optimisation), is a different job from SEO. If you want the primer first, start with What is AI search visibility? and come back.
What is an AI buyer
An AI buyer is anyone who uses an AI assistant to research a purchase: a founder asking ChatGPT which analytics tool to pick, a marketer asking Perplexity for the best email platform, a freelancer asking Claude where to find work. Instead of scanning ten blue links, they get a written answer that names brands, compares them and often ends with a verdict.
That last part matters. Traditional search shows options and leaves the choosing to you. An AI assistant participates in the decision. So AI search visibility is not just "does the AI mention me", it is "does the AI recommend me at the moment the buyer decides". Those are very different questions, and the gap between them is where most brands get surprised.
A real AI buying journey, turn by turn
Here is the shape of that freelancer journey, which is typical of the 59 we ran.
Turn 1. The buyer opens broad: zero budget, UK, looking for networking and freelance work. Claude names eight brands, none of them the example brand.
Turn 2. The buyer clarifies: "I'm in HR and recruitment, specifically looking to build my freelance consulting practice in the mid-market space." They ask which communities contain actual hiring managers rather than other freelancers, and whether any of it "actually helps you build credibility or get referrals, or is it mostly a numbers game".
Turn 3. They interrogate a specific recommendation: is a paid membership worth it for networking alone, or is there a free way in first?
Turn 4. They reality-check another route entirely, subcontracting under an established consultancy, and ask how to approach a former employer "without looking like I'm just chasing easy money".
Turn 5. Before deciding, they sweep the field: "Before I settle on one, what else is out there that I haven't seen yet? I want to be sure I've considered the full range."
Five turns, five different sets of brands named, and a decision at the end. A search keyword this was not.
Five ways AI buyers behave differently
They ask in paragraphs, not keywords
Nobody types "freelance jobs UK" into Claude. Our buyers wrote 80-word questions with three sub-questions and their constraints attached. The AI answers all of it at once, which means your brand is being evaluated against a far richer brief than any keyword ever carried.
They negotiate constraints out loud
Across the journeys, buyers stated budgets ("£30 to £80 per month for membership", "£3,000 to £8,000 per quarter for hiring tools"), regulatory needs (IR35 compliance came up constantly in this UK category), and commercial dealbreakers (commission rates, exclusivity lock-ins, who pays the platform fee). The models took these seriously and filtered brands accordingly. If your pricing page does not answer these questions clearly, the AI answers them for you, sometimes wrongly.
They ask what else is out there
The sweep question, "what have I not seen yet?", appeared near the end of most journeys. It is the moment a model reaches past the obvious names and pulls in challengers. In one journey it surfaced nine brands in a single answer. For smaller brands this is the door in; 316 brands got named at least once in this one category.
They reach a verdict, and explain it
Of our 59 journeys, 45 ended with the AI committing to a single recommendation. The reasons are written down, in full sentences. The example brand won ten of those decisions, and the winning reasons were consistent: no commission on earnings, a curated UK job board, community events, portfolio hosting. The losing reasons were just as consistent: no built-in contracting or IR35 handling, weaker fit for multi-disciplinary project coordination. One answer was blunt enough to sting, dismissing the brand's job feed as "low-paid spam". You will not find that sentence in any rank tracker, and it is exactly the sentence a brand in that position would need to read.
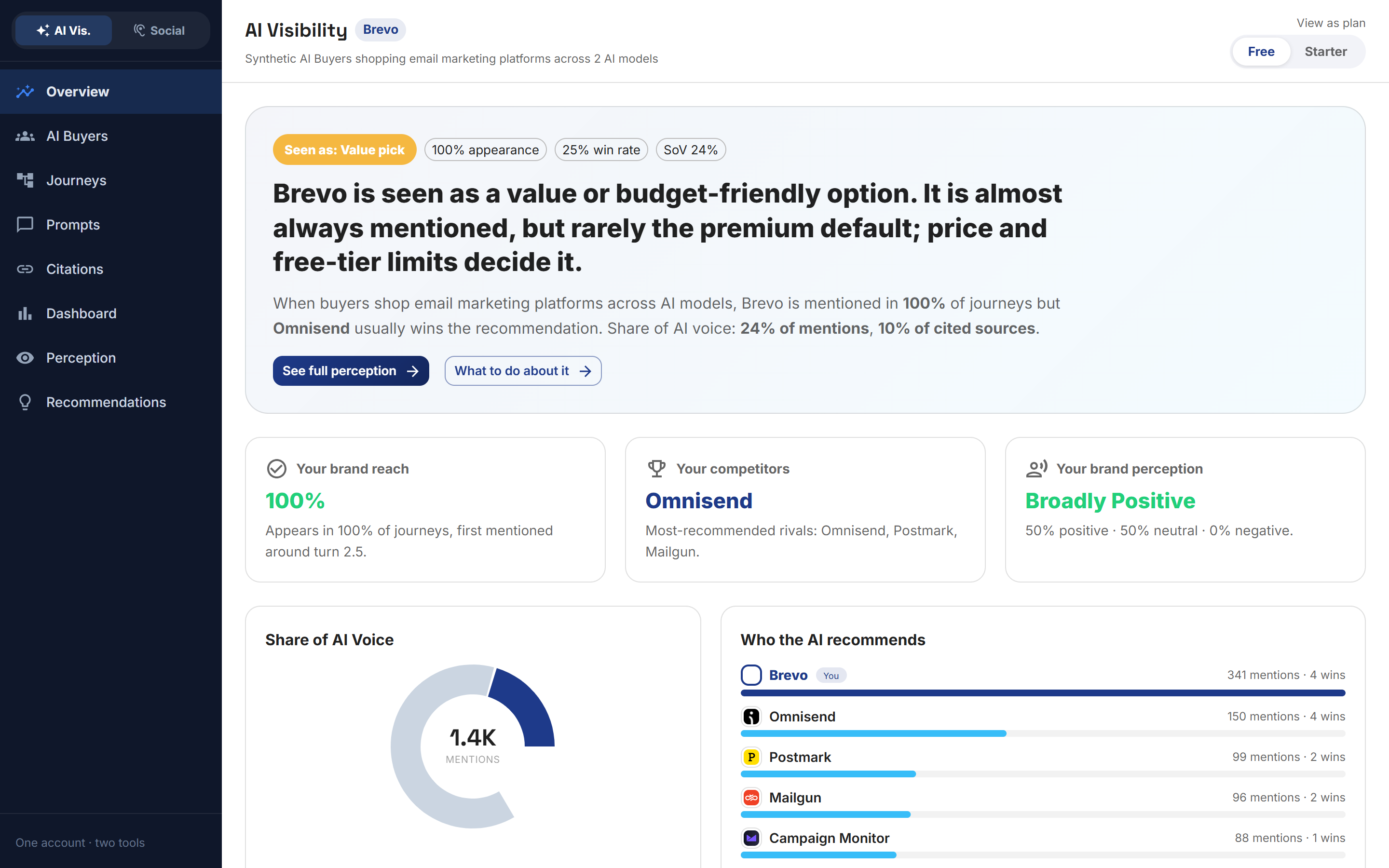
The same brand wins one buyer and loses another
This was the sharpest finding. For solo designers on a small monthly budget, the brand appeared in 100% of journeys and won 78% of their decisions. For boutique agency owners with £3,000 to £8,000 a quarter to spend, it appeared in 70% of journeys and won none. Same brand, same models, same week. AI visibility is not one number; it is a different number for every buyer type you care about.
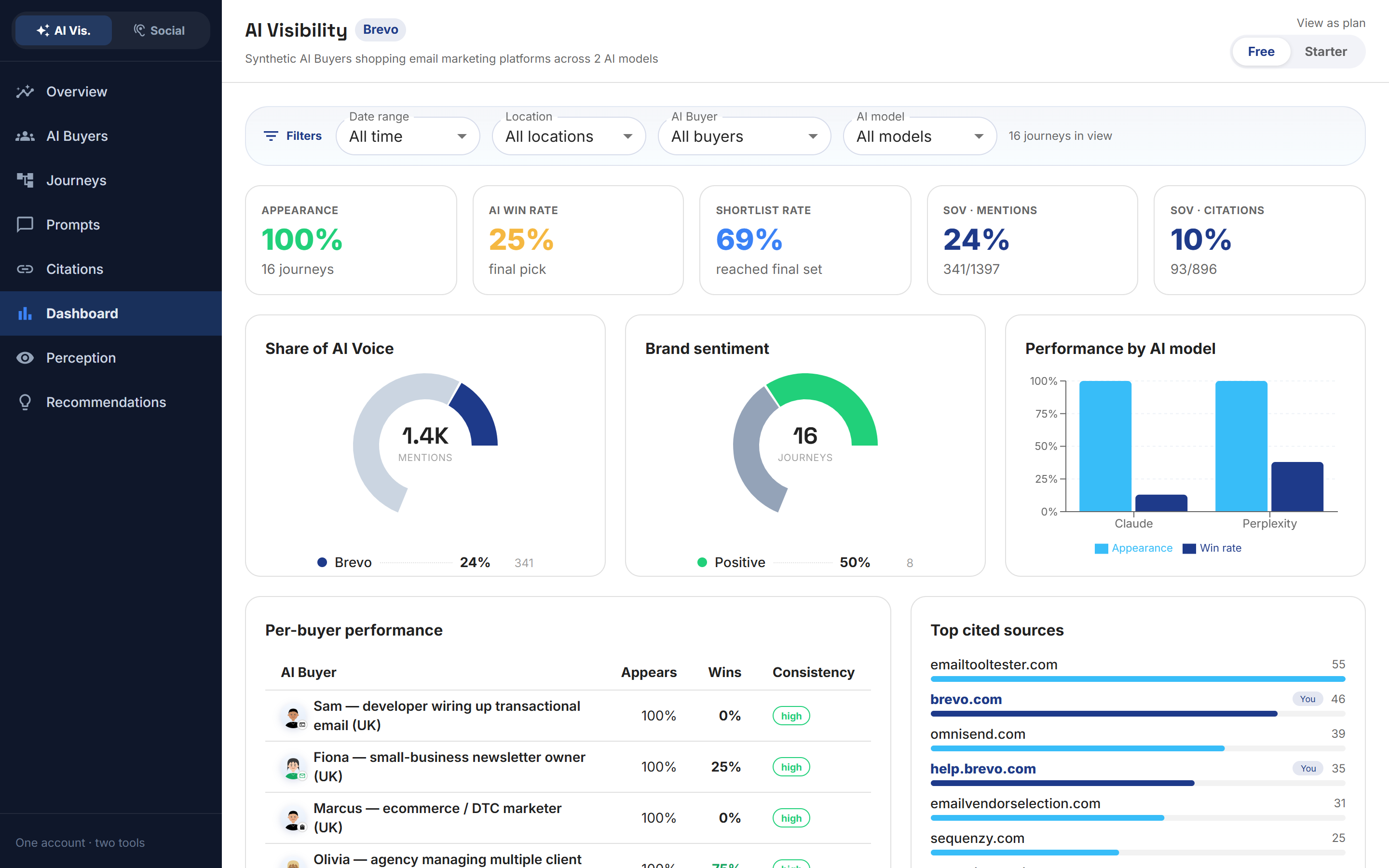
The metrics that describe AI search visibility
If you are going to manage this channel, these are the numbers we have found most useful, and the ones Babel42 reports:
- Appearance rate: the share of buying journeys in which you are named at all.
- Shortlist rate: how often you survive into the buyer's final comparison set.
- AI win rate: how often you are the recommendation at the decision point. This is the number that behaves most like revenue.
- Share of AI voice: your mentions as a share of all brand mentions in the category, and separately, how often the cited sources are yours.
- Win quality: whether you were named unprompted in the AI's first answer or only after nudging. Strong wins are worth more.
- Perception: how the AI characterises you when it talks about you, positive, neutral or negative, and the exact wording of what wins and loses you the deal.
Two honest caveats. First, these are estimates built from samples: a few dozen journeys per buyer per week, not a census of every conversation happening on ChatGPT. Treat the direction as reliable and individual percentage points as noise. Second, model behaviour shifts as vendors update models and their web search, which is why one-off audits age quickly and a weekly cadence matters.
What this can do for your business
We will not promise that AI visibility work triples your pipeline; nobody can measure that honestly yet. What it demonstrably gives you is three things.
A legible list of objections. Every lost decision comes with the reason written out. In our sweep the brand's most common losing theme was missing contracting and compliance features. That is not a marketing problem, it is a roadmap and positioning conversation, and now it is grounded in evidence rather than hunches.
Content you know is worth writing. Classic GEO and AEO advice says to publish clear, factual content that answers buyer questions and to earn credible third-party mentions, because AI answers draw on retrieval as well as training data. The journey transcripts tell you precisely which questions to answer: in this category, "does it handle IR35", "who pays the commission" and "is there an exclusivity lock-in" would each justify a page.
An early-warning system. Because buyers segment so sharply, you can see a competitor start winning one buyer type weeks before it would ever show in your revenue. In this sweep, a single run of journeys was enough to show exactly which segment the example brand dominates and which one it would need to either fight for or concede.
How to see your own numbers
Babel42's AI Visibility tool sends synthetic AI Buyers to shop your category across ChatGPT, Claude, Perplexity, Gemini and Grok, with live web search, multi-turn conversations and a decision at the end, then scores appearance, share of AI voice, win rate and perception, per buyer and per model.
The free plan runs one AI Buyer across Perplexity and ChatGPT on a weekly cadence, enough to learn whether AI assistants mention you at all and who is winning your category in the meantime. Setup takes a few minutes: tell it your brand, your category and who your buyers are, and it does the shopping.
Notes on method
The numbers in this article come from a single Babel42 example sweep, with the measured brand's name removed: 59 journeys, 293 prompts and 45 decided outcomes across five AI models in a single UK category (HR and recruitment), collected in early July 2026. Buyer personas were synthetic; model answers were real and included live web search. Sentiment and perception labels are produced by Babel42's AI and, like all automated analysis, are directional estimates rather than verdicts. Your category will behave differently, which is rather the point of measuring it.

